
Abstract
We introduce a novel 3D generative method, Generative 3D Reconstruction (G3DR) in ImageNet, capable of generating diverse and high-quality 3D objects from single images, addressing the limitations of existing methods.
At the heart of our framework is a novel depth regularization technique that enables the generation of scenes with high-geometric fidelity. G3DR also leverages a pretrained language-vision model, such as CLIP, to enable reconstruction in novel views and improve the visual realism of generations. Additionally, G3DR designs a simple but effective sampling procedure to further improve the quality of generations. G3DR offers diverse and efficient 3D asset generation based on class or text conditioning. Despite its simplicity, G3DR is able to beat state-of-theart methods, improving over them by up to 22% in perceptual metrics and 90% in geometry scores, while needing only half of the training time.
Code is available at https://github.com/preddy5/G3DR
Results
Methods
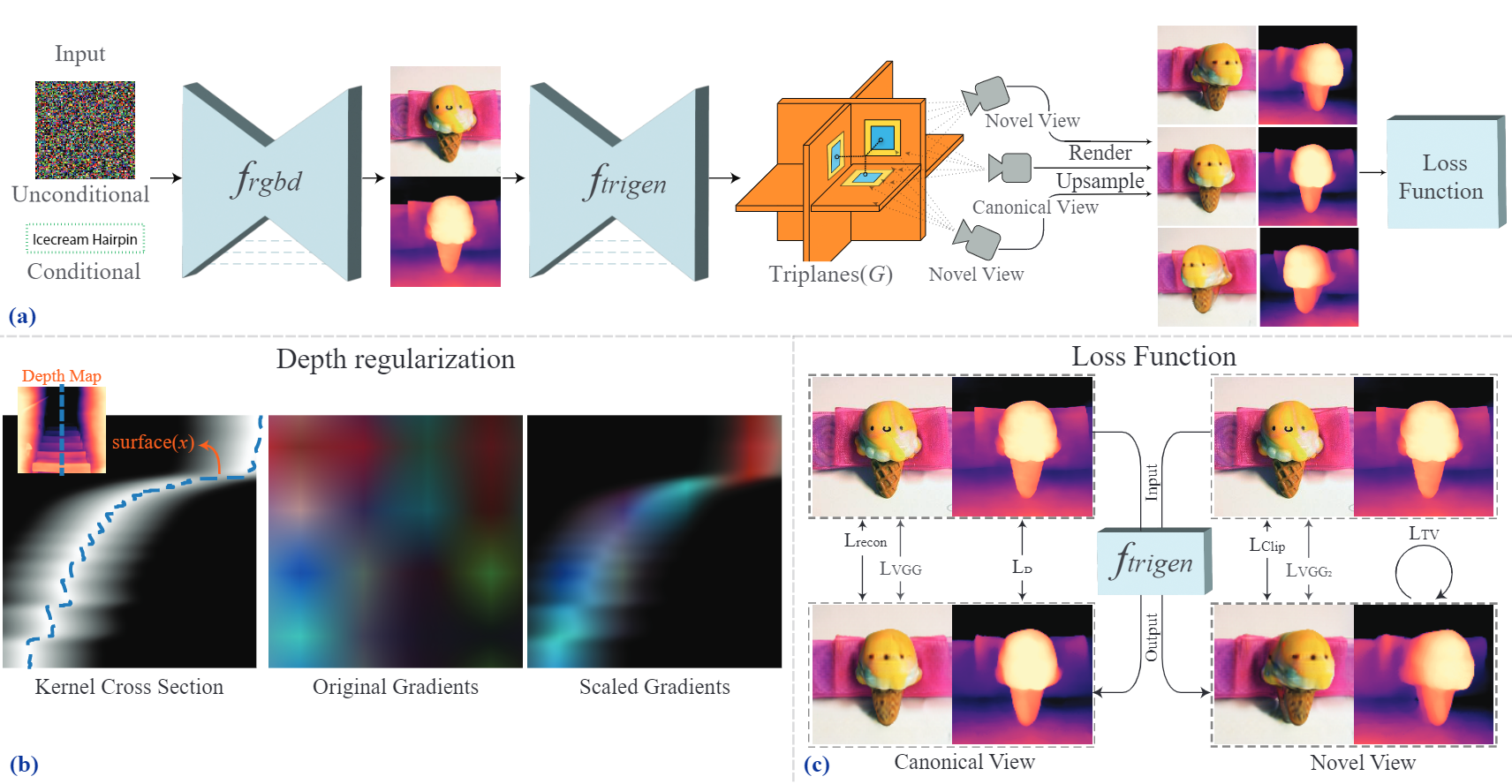
a) Our framework is conditioned on some visual input, class cateogry or text, and generates an image. Then it feeds that image over a triplane generator, and it finally renders it, ensuring good image quality and geometry using a regularization depth.
b) An illustration of our kernel in 2D; the blue line on the Depth Map represents the selected cross section, in the Original Gradients we visualize high dimensional gradients using rgb channels and Scaled Gradients show how the kernel modifies the volume rendering function gradients.
c) The losses of our model. In the canonical view, our method uses a combination of reconstruction, perceptual and depth loss. In the novel view, it uses a combination of clip, perceptual and tv loss. The losses are scaled accordingly, while the loss gradients during backpropagation are scaled based on the kernel in (b).
Quantitative results
Our method significantly outperforms the other 3D methods.
| Method | Synthesis | FID | IS |
|---|---|---|---|
| BigGAN (ArXiV18) | 2D | 8.7 | 142.3 |
| StyleGAN-XL (SIGGRAPH22) | 2D | 2.3 | 265.1 |
| ADM (NeurIPS21) | 2D | 4.6 | 186.7 |
| IVID 128x (ICCV23) | 2.5D | 14.1 | 61.4 |
| Ours 128x | 3D | 13.0 | 136.4 |
| EG3D (CVPR22) | 3D-a | 25.6 | 57.3 |
| StyleNeRF (ICML22) | 3D-a | 56.5 | 21.8 |
| 3DPhoto (CVPR20) | 3D-a | 116.6 | 9.5 |
| EpiGRAF (NeurIPS22) | 3D | 58.2 | 20.4 |
| 3DGP (ICLR23) | 3D | 19.7 | 124.8 |
| VQ3D (ICCV23) | 3D | 16.8 | n/a |
| Ours | 3D | 13.1 | 151.7 |