Pradyumna ReddyI am Research Scientist at Autodesk Research London. Before Autodesk I was a Research Scientist at Huawei Noah's Ark Lab London. Before that I was a PhD student working with Smart geometry Group, at University College London. My PhD advisor is Prof. Niloy J. Mitra. During my PhD I have had the opportunity to intern at Google Brain Amsterdam(Now Deepmind) and 2 x Adobe Research Creative Intelligence Lab. I completed my B.E Hons Computer Science and Engineering from BITS Pilani Goa, and did my undergrad-thesis at Harvard Medical School(Laboratory of Mathematics of Imaging, Psychiatry NeuroImaging Laboratory), where I worked with Prof. Yogesh Rathi. After that, I worked as a Statistical Analyst with the Data and Analytics group at Walmart Labs for a couple of years. Following which I joined UCL. CV / LinkedIn / Email / Google Scholar / GitHub |
|
ResearchCurrently, my research is focused on high-resolution 3D generative models. Over the years, I have worked on diverse topics that include tractography(Brain Imaging), vector graphics, graphs, and audio. During my PhD I am broadly working on using learning-based algorithms for analysis of unstructured data like graphs, vector graphics, and 3D data representations. |
PublicationsPlease find an updated list here: Google Scholar. The below list includes papers accepted to conferences or journals and pre-prints. (Outdated) |

|
G3DR: Generative 3D Reconstruction in ImageNetPradyumna Reddy, Ismail Elezi, Jiankang Deng CVPR 2024 Website / Paper / Code / We introduce a novel 3D generative method, Generative 3D Reconstruction (G3DR) in ImageNet, capable of generating diverse and high-quality 3D objects from single images, addressing the limitations of existing methods. At the heart of our framework is a novel depth regularization technique that enables the generation of scenes with high-geometric fidelity. G3DR also leverages a pretrained language-vision model, such as CLIP, to enable reconstruction in novel views and improve the visual realism of generations. Additionally, G3DR designs a simple but effective sampling procedure to further improve the quality of generations. G3DR offers diverse and efficient 3D asset generation based on class or text conditioning. Despite its simplicity, G3DR is able to beat state-of-theart methods, improving over them by up to 22% in perceptual metrics and 90% in geometry scores, while needing only half of the training time. |
|
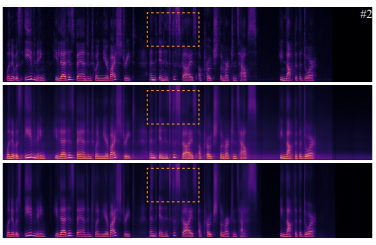
AudioSlots: A slot-centric generative model for audio separationPradyumna Reddy, Scott Wisdom, Klaus Greff, John R. Hershey, Thomas Kipf ICASSP(SASB) 2023 Paper / In a range of recent works, object-centric architectures have been shown to be suitable for unsupervised scene decomposition in the vision domain. Inspired by these methods we present AudioSlots, a slot-centric generative model for blind source separation in the audio domain. AudioSlots is built using permutation-equivariant encoder and decoder networks. The encoder network based on the Transformer architecture learns to map a mixed audio spectrogram to an unordered set of independent source embeddings. The spatial broadcast decoder network learns to generate the source spectrograms from the source embeddings. We train the model in an end-to-end manner using a permutation invariant loss function. Our results on Libri2Mix speech separation constitute a proof of concept that this approach shows promise. We discuss the results and limitations of our approach in detail, and further outline potential ways to overcome the limitations and directions for future work. |

|
Search for Concepts: Discovering Visual Concepts Using Direct OptimizationPradyumna Reddy, Paul Guerrero, Niloy J. Mitra BMVC 2022 Website / Paper / Code / Finding an unsupervised decomposition of an image into individual objects is a key step to leverage compositionality and to perform symbolic reasoning. Traditionally, this problem is solved using amortized inference, which does not generalize beyond the scope of the training data, may sometimes miss correct decompositions, and requires large amounts of training data. We propose finding a decomposition using direct, unamortized optimization, via a combination of a gradient-based optimization for differentiable object properties and global search for non-differentiable properties. We show that using direct optimization is more generalizable, misses fewer correct decompositions, and typically requires less data than methods based on amortized inference. This highlights a weakness of the current prevalent practice of using amortized inference that can potentially be improved by integrating more direct optimization elements. |
|
|
A Multi-Implicit Neural Representation for FontsPradyumna Reddy, Zhifei Zhang, Matthew Fisher, Hailin Jin, Zhaowen Wang, Niloy J. Mitra NeurIPS 2021 Website / Paper / Code / Fonts are ubiquitous across documents and come in a variety of styles. They are either represented in a native vector format or rasterized to produce fixed resolution images. In the first case, the non-standard representation prevents benefiting from latest network architectures for neural representations; while, in the latter case, the rasterized representation, when encoded via networks, results in loss of data fidelity, as font-specific discontinuities like edges and corners are difficult to represent using neural networks. Based on the observation that complex fonts can be represented by a superposition of a set of simpler occupancy functions, we introduce \textit{multi-implicits} to represent fonts as a permutation-invariant set of learned implict functions, without losing features (e.g., edges and corners). However, while multi-implicits locally preserve font features, obtaining supervision in the form of ground truth multi-channel signals is a problem in itself. Instead, we propose how to train such a representation with only local supervision, while the proposed neural architecture directly finds globally consistent multi-implicits for font families. We extensively evaluate the proposed representation for various tasks including reconstruction, interpolation, and synthesis to demonstrate clear advantages with existing alternatives. Additionally, the representation naturally enables glyph completion, wherein a single characteristic font is used to synthesize a whole font family in the target style. |
|
|
Im2Vec: Synthesizing Vector Graphics without Vector SupervisionPradyumna Reddy, Michael Gharbi, Michal Lukac, Niloy J. Mitra CVPR 2021 Selected for Oral Presentation Top-10 most popular papers at CVPR 2021(Source: CVPR Buzz) Website / Paper / Code / Supplementary / Vector graphics are widely used to represent fonts, logos, digital artworks, and graphic designs. But, while a vast body of work has focused on generative algorithms for raster images, only a handful of options exists for vector graphics. One can always rasterize the input graphic and resort to image-based generative approaches, but this negates the advantages of the vector representation. The current alternative is to use specialized models that require explicit supervision on the vector graphics representation at training time. This is not ideal because large-scale high quality vector-graphics datasets are difficult to obtain. Furthermore, the vector representation for a given design is not unique, so models that supervise on the vector representation are unnecessarily constrained. Instead, we propose a new neural network that can generate complex vector graphics with varying topologies, and only requires indirect supervision from readily-available raster training images (i.e., with no vector counterparts). To enable this, we use a differentiable rasterization pipeline that renders the generated vector shapes and composites them together onto a raster canvas. We demonstrate our method on a range of datasets, and provide comparison with state-of-the-art SVG-VAE and DeepSVG, both of which require explicit vector graphics supervision. Finally, we also demonstrate our approach on the MNIST dataset, for which no groundtruth vector representation is available. |
|
|
Discovering Pattern Structure Using Differentiable CompositingPradyumna Reddy, Paul Guerrero, Matt Fisher, Wilmot Li, Niloy J. Mitra Siggraph Asia 2020 Website / Paper / Code / Patterns, which are collections of elements arranged in regular or near-regular arrangements, are an important graphic art form and widely used due to their elegant simplicity and aesthetic appeal. When a pattern is encoded as a flat image without the underlying structure, manually editing the pattern is tedious and challenging as one has to both preserve the individual element shapes and their original relative arrangements. State-of-the-art deep learning frameworks that operate at the pixel level are unsuitable for manipulating such patterns. Specifically, these methods can easily disturb the shapes of the individual elements or their arrangement, and thus fail to preserve the latent structures of the input patterns. We present a novel differentiable compositing operator using pattern elements and use it to discover structures, in the form of a layered representation of graphical objects, directly from raw pattern images. This operator allows us to adapt current deep learning based image methods to effectively handle patterns. We evaluate our method on a range of patterns and demonstrate superiority in the context of pattern manipulations when compared against state-of-the-art pixel-based pixel- or point-based alternatives. |
|
|
SeeThrough: Finding Objects in Heavily Occluded Indoor Scene ImagesMoos Hueting, Pradyumna Reddy, Ersin Yumer, Vladimir G. Kim, Nathan Carr, Niloy J. Mitra 3DV 2018 Selected for Oral Presentation Website / Paper / Code / Discovering 3D arrangements of objects from single indoor images is important given its many applications including interior design, content creation, etc. Although heavily researched in the recent years, existing approaches break down under medium or heavy occlusion as the core object detection module starts failing in absence of directly visible cues. Instead, we take into account holistic contextual 3D information, exploiting the fact that objects in indoor scenes co-occur mostly in typical near-regular configurations. First, we use a neural network trained on real indoor annotated images to extract 2D keypoints, and feed them to a 3D candidate object generation stage. Then, we solve a global selection problem among these 3D candidates using pairwise co-occurrence statistics discovered from a large 3D scene database. We iterate the process allowing for candidates with low keypoint response to be incrementally detected based on the location of the already discovered nearby objects. Focusing on chairs, we demonstrate significant performance improvement over combinations of state-of-the-art methods, especially for scenes with moderately to severely occluded objects. |
|
|
Joint Multi-Fiber NODDI Parameter Estimation and Tractography Using the Unscented Information FilterPradyumna Reddy*, Yogesh Rathi Frontiers of Neuroscience 2016 (Most cited Journal in Neuroscience) Paper / Tracing white matter fiber bundles is an integral part of analyzing brain connectivity. An accurate estimate of the underlying tissue parameters is also paramount in several neuroscience applications. In this work, we propose to use a joint fiber model estimation and tractography algorithm that uses the NODDI (neurite orientation dispersion diffusion imaging) model to estimate fiber orientation dispersion consistently and smoothly along the fiber tracts along with estimating the intracellular and extracellular volume fractions from the diffusion signal. While the NODDI model has been used in earlier works to estimate the microstructural parameters at each voxel independently, for the first time, we propose to integrate it into a tractography framework. We extend this framework to estimate the NODDI parameters for two crossing fibers, which is imperative to trace fiber bundles through crossings as well as to estimate the microstructural parameters for each fiber bundle separately. We propose to use the unscented information filter (UIF) to accurately estimate the model parameters and perform tractography. The proposed approach has significant computational performance improvements as well as numerical robustness over the unscented Kalman filter (UKF). Our method not only estimates the confidence in the estimated parameters via the covariance matrix, but also provides the Fisher-information matrix of the state variables (model parameters), which can be quite useful to measure model complexity. Results from in-vivo human brain data sets demonstrate the ability of our algorithm to trace through crossing fiber regions, while estimating orientation dispersion and other biophysical model parameters in a consistent manner along the tracts. |
|
|
A Braille-based mobile communication and translation glove for deaf-blind peopleTanay Choudhary*, Saurabh Kulkarni*, Pradyumna Reddy* ICPC 2015 Paper / Deafblind people are excluded from most forms of communication and information. This paper suggests a novel approach to support the communication and interaction of deaf- blind individuals, thus fostering their independence. It includes a smart glove that translates the Braille alphabet, which is used almost universally by the literate deafblind population, into text and vice versa, and communicates the message via SMS to a remote contact. It enables user to convey simple messages by capacitive touch sensors as input sensors placed on the palmer side of the glove and converted to text by the PC/mobile phone. The wearer can perceive and interpret incoming messages by tactile feedback patterns of mini vibrational motors on the dorsal side of the glove. The successful implementation of real-time two- way translation between English and Braille, and communication of the wearable device with a mobile phone/PC opens up new opportunities of information exchange which were hitherto un-available to deafblind individuals, such as remote communication, as well as parallel one-to many broadcast. The glove also makes communicating with laypersons without knowledge of Braille possible, without the need for trained interpreters. |
|
|
Selective Visualization of Anomalies in Fundus Images via Sparse and Low Rank DecompositionAmol Mahurkar*, Ameya Joshi*, Naren Nallapareddy*, Pradyumna Reddy*, Micha Feigin, Achuta Kadambi, Ramesh Raskar Siggraph Poster 2014 Paper / |
|
Design and source code from Jon Barron's website |